if(!require(pacman)){
install.packages("pacman")
}
pacman::p_load(tidyverse,rvest, here)Web scraping com R
O web scraping é uma técnica poderosa para coletar dados de sites de forma automatizada. Com a linguagem R e o pacote rvest, você pode extrair informações de páginas da web de maneira eficiente.
Neste exemplo, vamos fazer web scraping de uma loja online de livros, extraindo títulos e preços de várias páginas.
Pacotes
Etapas
criar um dataframe vazio para receber os dados;
criar um loop para acessar as páginas;
2.1 criar um objeto com a URL da página usando o
paste0e o componenteisendo o padrão a ser mudado;2.2 usar o
rvest::read_htmlpara ler o conteúdo da página;-
2.3 usar o
rvest::html_nodesextrair os títulos e preços dos livros;- 2.3.1 os códigos usados no
html_nodes()foram obtidos com o SelectorGadget, conforme Figura 1;
- 2.3.1 os códigos usados no
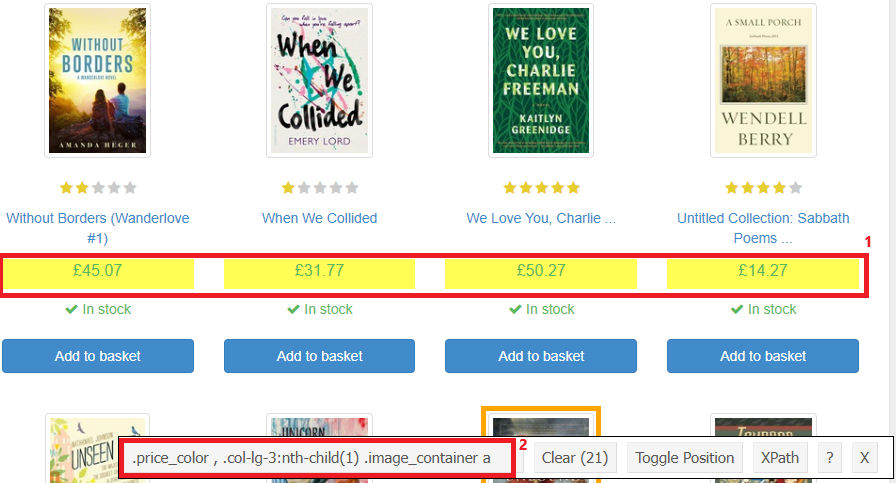
2.4 combinar os dados em um dataframe;
2.5 acrescentar as novas informações ao final do data-frame;
2.6 usar o
Sys.sleeppara evitar sobrecarregar o servidor.
Código
# cria um dataframe vazio
dados_loop <- data.frame()
# criar um loop para acessar as páginas
for (i in seq(from = 1, to = 3, by = 1)){
# salva o endereço da página com o i como elemento do loop
url_loop <- base::paste0("https://books.toscrape.com/catalogue/page-",i,".html")
# lê o conteúdo da página
web_pag_loop <- rvest::read_html(url_loop)
# extrai os títulos e preços dos livros
titulo <- rvest::html_nodes(
web_pag_loop,
"h3 a , .col-lg-3:nth-child(1) a"
) |>
rvest::html_text()
preco <- rvest::html_nodes(
web_pag_loop,
".price_color , .col-lg-3:nth-child(1) .image_container a"
) |>
rvest::html_text()
# combinar os dados em um dataframe
pag_dados <- base::data.frame(titulo, preco)
# acrescentar as novas informações ao final do data-frame
dados_loop <- base::rbind(dados_loop, pag_dados)
# usar o Sys.sleep para evitar sobrecarregar o servidor
Sys.sleep(3)
}
dados_loop |>
head() titulo preco
1
2 A Light in the ... £51.77
3 Tipping the Velvet £53.74
4 Soumission £50.10
5 Sharp Objects £47.82
6 Sapiens: A Brief History ... £54.23Como resultado nós obtemos um dataframe com títulos e preços dos livros. Mas precisamos alterar o preço para numérico e remover o símbolo da moeda. Poderíamos ter feito isso dentro do loop, mas eu preferi fazer separadamente.
dados_loop_2 <- dados_loop |>
dplyr::mutate(
dplyr::across(
.cols = tidyr::contains("pre"),
.fns = readr::parse_number)
) |>
tidyr::drop_na()
dados_loop_2 |>
dplyr::slice_head(n=6) titulo preco
1 A Light in the ... 51.77
2 Tipping the Velvet 53.74
3 Soumission 50.10
4 Sharp Objects 47.82
5 Sapiens: A Brief History ... 54.23
6 The Requiem Red 22.65Conclusão
O web scraping com R, usando o pacote rvest, é uma ferramenta incrivelmente útil para coletar dados de sites de forma automatizada. Neste exemplo, vimos como extrair títulos e preços de livros de uma loja online, passando por várias páginas com um loop e organizando tudo em um dataframe. Também fizemos uma limpeza básica dos dados, transformando os preços em números e removendo os símbolos de moeda.
Com as técnicas apresentadas aqui, você pode adaptar o código para coletar dados de outros sites, explorar diferentes layouts de páginas e até mesmo combinar o web scraping com outras etapas da análise de dados. O R, junto com o rvest, abre um leque de oportunidades para quem trabalha com dados na web, desde a coleta até a análise e visualização.
Nos vemos na próxima postagem, Aldani👋.